Temporal Cycle-Consistency Learning
Abstract
We introduce a self-supervised representation learning method based on the task of temporal alignment between videos. The method trains a network using temporal cycle-consistency (TCC), a differentiable cycle-consistency loss that can be used to find correspondences across time in multiple videos. The resulting per-frame embeddings can be used to align videos by simply matching frames using nearest-neighbors in the learned embedding space.
To evaluate the power of the embeddings, we densely label the Pouring and Penn Action video datasets for action phases. We show that (i) the learned embeddings enable few-shot classification of these action phases, significantly reducing the supervised training requirements; and (ii) TCC is complementary to other methods of self-supervised learning in videos, such as Shuffle and Learn and Time-Contrastive Networks. The embeddings are also used for a number of applications based on alignment (dense temporal correspondence) between video pairs, including transfer of metadata of synchronized modalities between videos (sounds, temporal semantic labels), synchronized playback of multiple videos, and anomaly detection.
Introduction
The world presents us with abundant examples of sequential processes. A plant growing from a seedling to a tree, the daily routine of getting up, going to work and coming back home, or a person pouring themselves a glass of water -- are all examples of events that happen in a particular order. Videos capturing such processes not only contain information about the causal nature of these events, but also provide us with a valuable signal -- the possibility of temporal correspondences lurking across multiple instances of the same process. For example, during pouring, one could be reaching for a teapot, a bottle of wine, or a glass of water to pour from. Key moments such as the first touch to the container or the container being lifted from the ground are common to all pouring sequences. These correspondences, which exist in spite of many varying factors like visual changes in viewpoint, scale, container style, the speed of the event, etc., could serve as the link between raw video sequences and high-level temporal abstractions (e.g. phases of actions). In this work we present evidence that suggests the very act of looking for correspondences in sequential data enables the learning of rich and useful representations, particularly suited for fine-grained temporal understanding of videos.
Temporal reasoning in videos, understanding multiple stages of a process and causal relations between them, is a relatively less studied problem compared to recognizing action categories
When frame-by-frame alignment (i.e. supervision) is available, learning correspondences reduces to learning a common embedding space from pairs of aligned frames (e.g. CCA
The main contribution of this paper is a new self-supervised training method, referred to as temporal cycle consistency (TCC) learning, that learns representations by aligning video sequences of the same action. We compare TCC representations against features from existing self-supervised video representation methods
Related Work
Cycle consistency. Validating good matches by cycling between two or more samples is a commonly used technique in computer vision. It has been applied successfully for tasks like co-segmentation
For instance, FlowWeb
Video alignment. When we have synchronization information (e.g. multiple cameras recording the same event) then learning a mapping between multiple video sequences can be accomplished by using existing methods such as Canonical Correlation Analysis (CCA)
Action localization and parsing. As action recognition is quite popular in the computer vision community, many studies
Soft nearest neighbours. The differentiable or soft formulation for nearest-neighbors is a commonly known method
Self-supervised representations. There has been significant progress in learning from images and videos without requiring class or temporal segmentation labels. Instead of labels, self-supervised learning methods use signals such as temporal order
Cycle Consistent Representation Learning
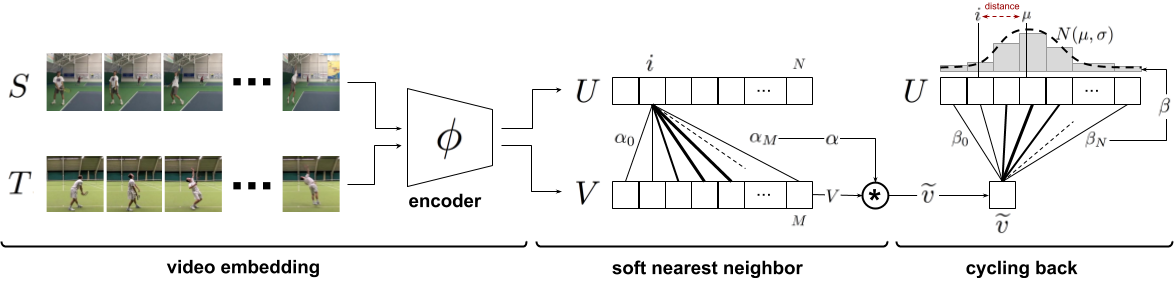
Figure 4: Temporal cycle consistency. The embedding sequences and are obtained by encoding video sequences and with the encoder network , respectively. For the selected point in , soft nearest neighbor computation and cycling back to again is demonstrated visually. Finally the normalized distance between the index and cycling back distribution (which is fitted to ) is minimized.
The core contribution of this work is a self-supervised approach to learn an embedding space where two similar video sequences can be aligned temporally. More specifically, we intend to maximize the number of points that can be mapped one-to-one between two sequences by using the minimum distance in the learned embedding space. We can achieve such an objective by maximizing the number of cycle-consistent frames between two sequences (see Figure 3). However, cycle-consistency computation is typically not a differentiable procedure. In order to facilitate learning such an embedding space using back-propagation, we introduce two differentiable versions of the cycle-consistency loss, which we describe in detail below.
Given any frame in a sequence , the embedding is computed as , where is the neural network encoder parameterized by . For the following sections, assume we are given two video sequences and , with lengths and , respectively. Their embeddings are computed as and such that and .
Cycle-consistency
In order to check if a point is cycle consistent, we first determine its nearest neighbor, . We then repeat the process to find the nearest neighbor of in , i.e. . The point is cycle-consistent if and only if , in other words if the point cycles back to itself. Figure 3 provides positive and negative examples of cycle consistent points in an embedding space. We can learn a good embedding space by maximizing the number of cycle-consistent points for any pair of sequences. However that would require a differentiable version of cycle-consistency measure, two of which we introduce below.
Cycle-back Classification
We first compute the soft nearest neighbor of in , then figure out the nearest neighbor of back in . We consider each frame in the first sequence to be a separate class and our task of checking for cycle-consistency reduces to classification of the nearest neighbor correctly. The logits are calculated using the distances between and any , and the ground truth label are all zeros except for the index which is set to 1.
For the selected point , we use the softmax function to define its soft nearest neighbor as:
(1)
and is the the similarity distribution which signifies the proximity between and each . And then we solve the class (i.e.\ number of frames in ) classification problem where the logits are and the predicted labels are . Finally we optimize the cross-entropy loss as follows:
(2)
Cycle-back Regression
Although cycle-back classification defines a differentiable cycle-consistency loss function, it has no notion of how close or far in time the point to which we cycled back is. We want to penalize the model less if we are able to cycle back to closer neighbors as opposed to the other frames that are farther away in time. In order to incorporate temporal proximity in our loss, we introduce cycle-back regression. A visual description of the entire process is shown in Figure 4. Similar to the previous method first we compute the soft nearest neighbor of in . Then we compute the similarity vector that defines the proximity between and each as:
(3)
Note that is a discrete distribution of similarities over time and we expect it to show a peaky behavior around the index in time. Therefore, we impose a Gaussian prior on by minimizing the normalized squared distance as our objective. We enforce to be more peaky around by applying additional variance regularization. We define our final objective as:
where and , and is the regularization weight. Note that we minimize the log of variance as using just the variance is more prone to numerical instabilities. All these formulations are differentiable and can conveniently be optimized with conventional back-propagation.
Implementation details
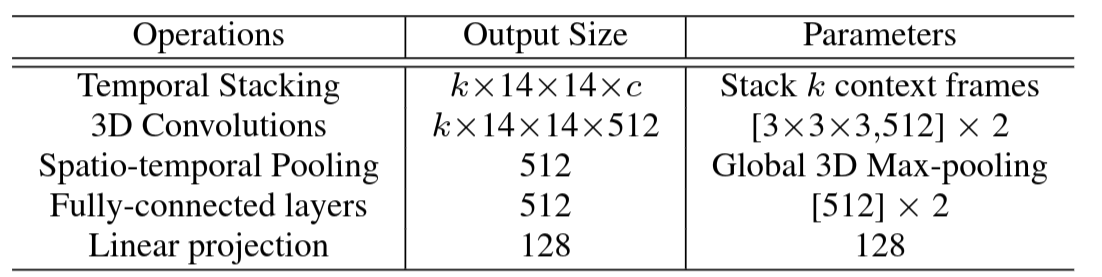
Training Procedure. Our self-supervised representation is learned by minimizing the cycle-consistency loss for all the pair of sequences in the training set. Given a sequence pair, their frames are embedded using the encoder network and we optimize cycle consistency losses for randomly selected frames within each sequence until convergence. We used Tensorflow
Encoding Network. All the frames in a given video sequence are resized to . When using ImageNet pretrained features, we use ResNet-50
Datasets and Evaluation

We validate the usefulness of our representation learning technique on
two datasets: (i) Pouring
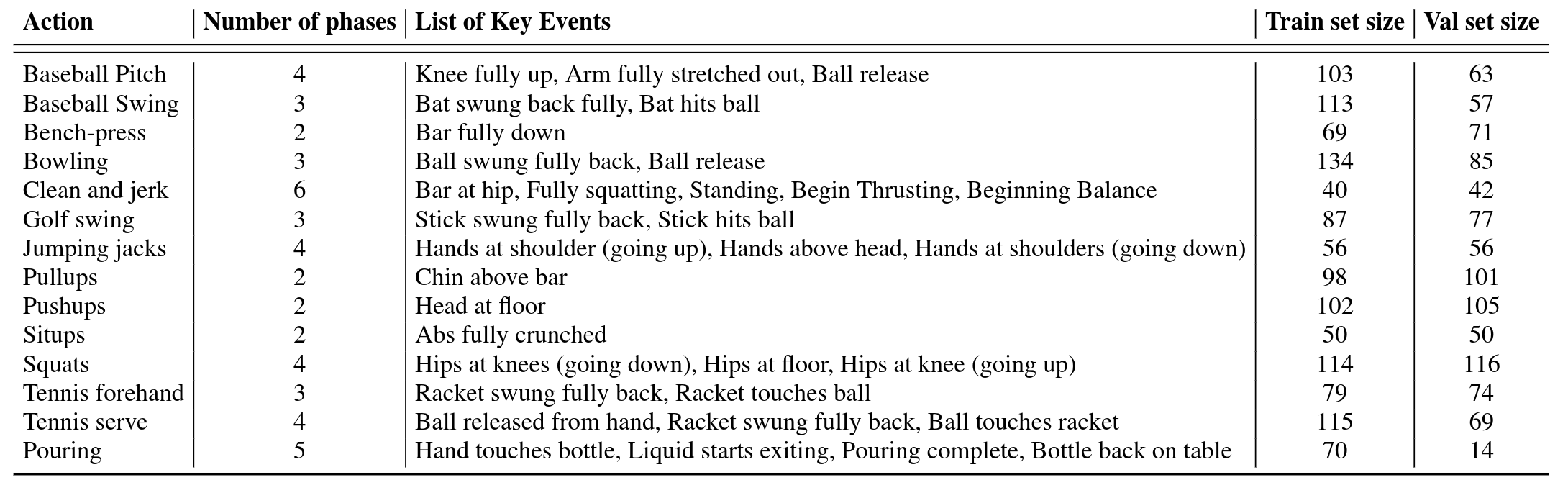
Annotations. For evaluation purposes, we add two types of labels to the video frames of
these datasets: key events and phases.
Densely labeling each frame in a video is a difficult and
time-consuming task. Labelling only key events both reduces the number of frames
that need to be annotated, and also reduces
the ambiguity of the task (and thus the
disagreement between annotators). For example, annotators agree more
about the frame when the golf club hits the ball (a key event) than when the
golf club is at a certain angle. The phase is the period between two key events, and all frames in the
period have the same phase label. It is similar to tasks proposed in
We use all the real videos from the Pouring dataset, and all but two action categories
in Penn Action. We do not use
Strumming guitar and Jumping rope because
it is difficult to define unambiguous key events for these. We
use the train/val splits of the original
datasets
Evaluation
We use three evaluation measures computed on the validation set. These metrics evaluate the model on fine-grained temporal understanding of a given action. Note, the networks are first trained on the training set and then frozen. SVM classifiers and linear regressors are trained on the features from the networks, with no additional fine-tuning of the networks. For all measures a higher score implies a better model.
1. Phase classification accuracy: is the per frame phase classification accuracy. This is implemented by training a SVM classifier on the phase labels for each frame of the training data.
2. Phase progression:
measures how well the progress of a process or action is captured by the embeddings. We first define
an approximate measure of progress through a phase
as the difference in time-stamps between any
given frame and each key event. This is normalized by the number of
frames present in that video. Similar definitions can be found in recent literature
where is the ground truth event progress value, is the mean of all and is the prediction made by the linear regression model. The maximum value of this measure is .
3. Kendall's Tau
We refer the reader to
Experiments
Baselines
We compare our representations with existing self-supervised video representation learning methods. For completeness, we briefly describe the baselines below but recommend referring to the original papers for more details.
Shuffle and Learn (SaL)
Time-Constrastive Networks (TCN)
Combined Losses. In addition to these baselines, we can combine our cycle consistency loss with both SaL and TCN to get two more training methods: TCC+SaL and TCC+TCN. We learn the embedding by computing both losses and adding them in a weighted manner to get the total loss, based on which the gradients are calculated. The weights are selected by performing a search over 3 values . All baselines share the same video encoder architecture, as described in section Implementation Details.
Ablation of Different Cycle Consistency Losses
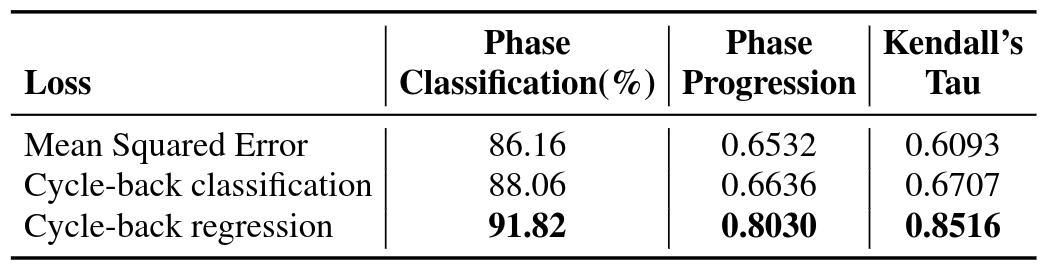
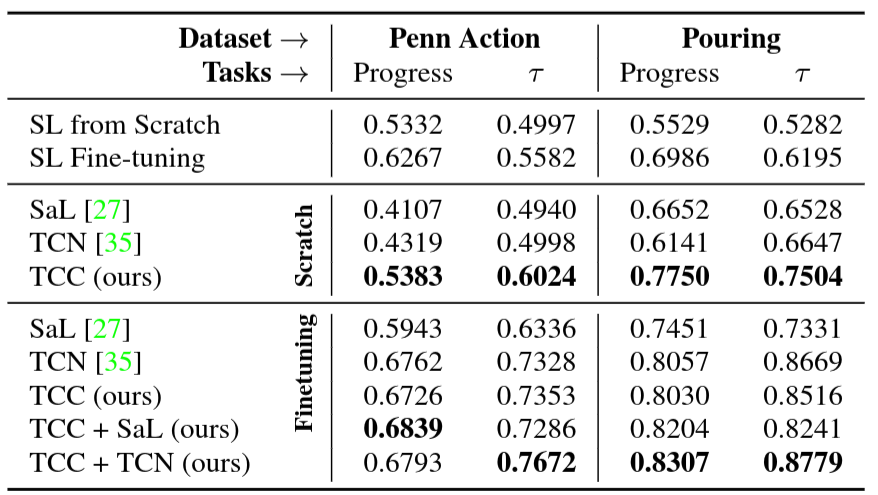
We ran an experiment on the Pouring dataset to see how the different losses compare against each other. We also report metrics on the Mean Squared Error (MSE) version of the cycle-back regression loss (Equation 4) which is formulated by only minimizing , ignoring the variance of predictions altogether. We present the results in Table 3 and observe that the variance aware cycle-back regression loss outperforms both of the other losses in all metrics. We name this version of cycle-consistency as the final temporal cycle consistency (TCC) method, and use this version for the rest of the experiments.
Action Phase Classification
Self-supervised Learning from Scratch. We perform experiments to compare different self-supervised methods for learning visual representations from scratch. This is a challenging setting as we learn the entire encoder from scratch without labels.
We use a smaller encoder model (i.e.\ VGG-M
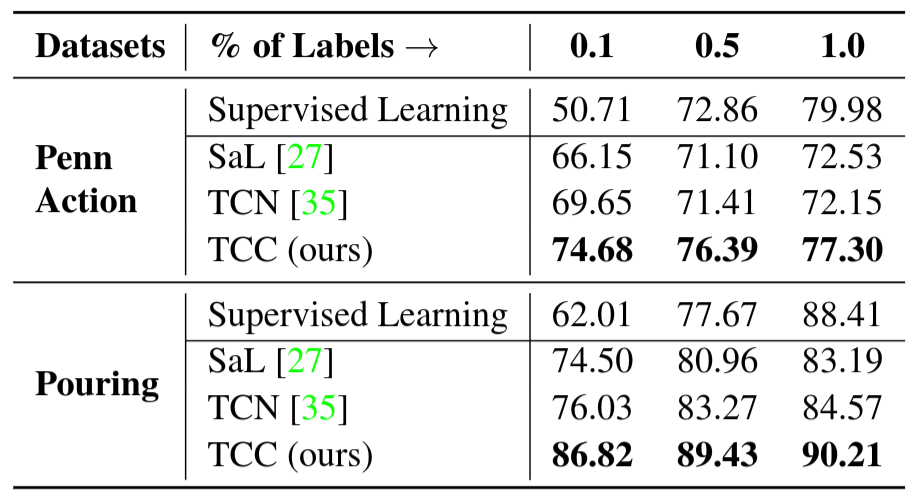
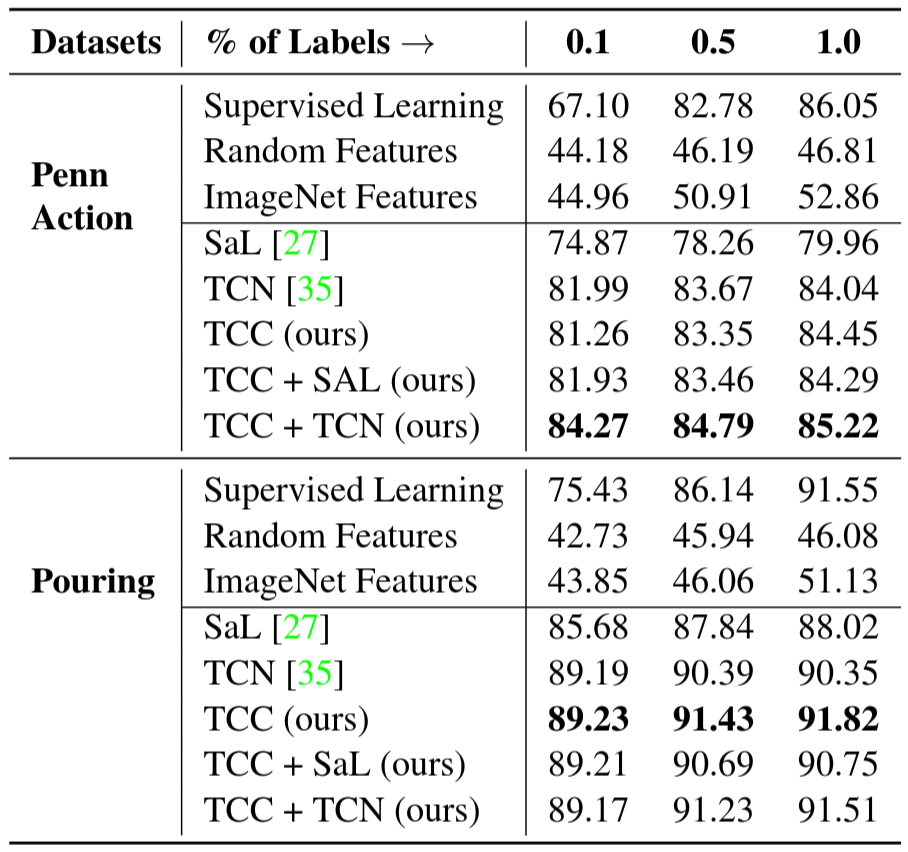
Self-supervised Fine-tuning. Features from networks trained for the task of image classification on the ImageNet dataset have been used for many other vision tasks. They are also useful because initializing from weights of pre-trained networks leads to faster convergence. We train all the representation learning methods mentioned in Section Evaluation and report the results on the Pouring and Penn Action datasets in Table 5. Here the encoder model is a ResNet-50
Self-supervised Few Shot Learning. We also test the usefulness of our learned representations in the few-shot scenario: we have many training videos but per-frame labels are only available for a few of them. In this experiment, we use the same set-up as the fine-tuning experiment described above. The embeddings are learned using either a self-supervised loss or vanilla supervised learning. To learn the self-supervised features, we use the entire training set of videos. We compare these features against the supervised learning baseline where we train the model on the videos for which labels are available. Note that one labeled video means hundreds of labeled frames. In particular, we want to see how the performance on the phase classification task is affected by increasing the number of labeled videos. We present the results in Figure 6. We observe significant performance boost using self-supervised methods as opposed to just using supervised learning on the labeled videos. We present results from Golf Swing and Tennis Serve classes above. With only one labeled video, TCC and TCC+TCN achieve the performance that supervised learning achieves with about 50 densely labeled videos. This suggests that there is a lot of untapped signal present in the raw videos which can be harvested using self-supervision.
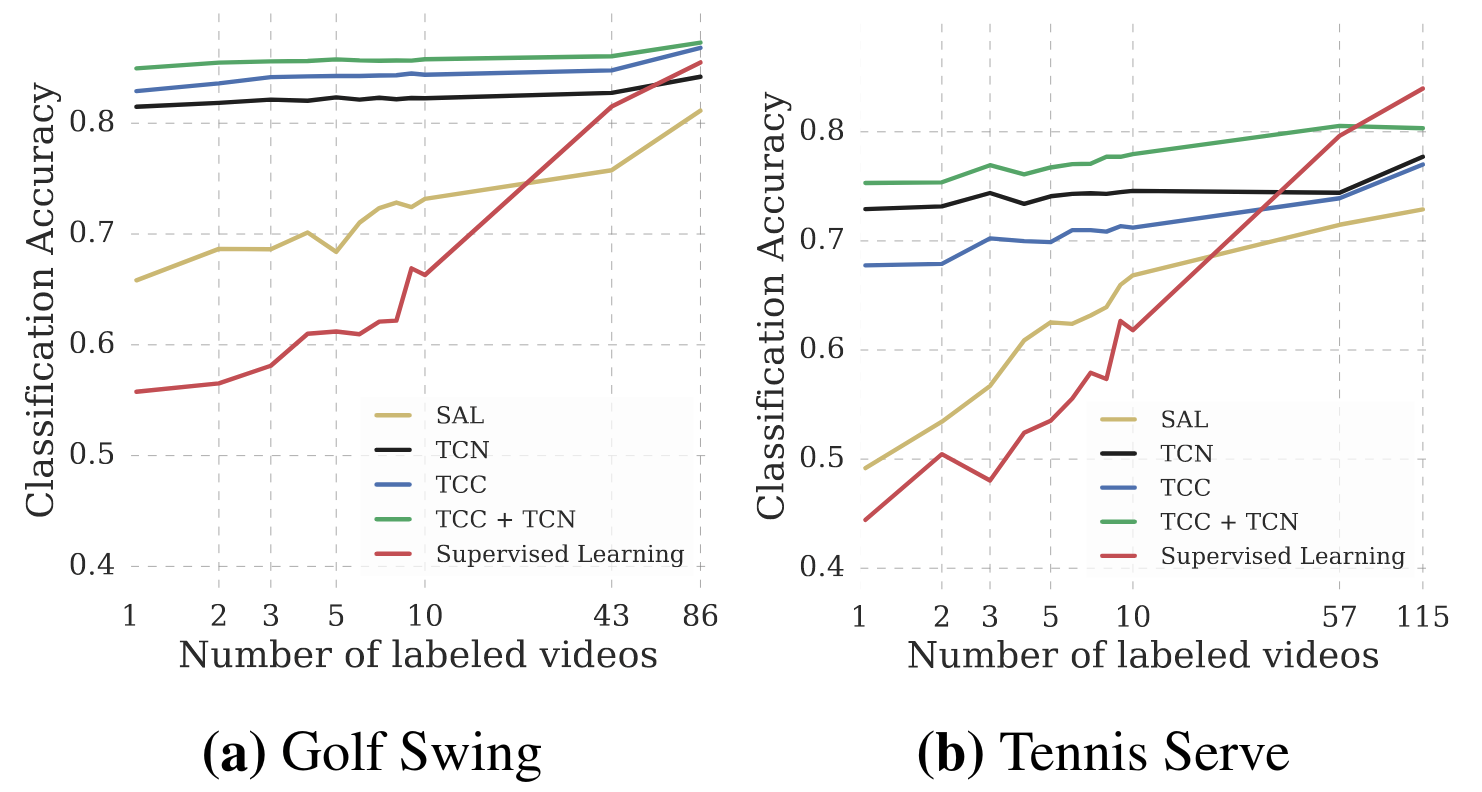
Phase Progression and Kendall's Tau
We evaluate the encodings for the remaining tasks described in Section Evaluation. These tasks measure the effectiveness of representations at a more fine-grained level than phase classification. We report the results of these experiments in Table 6. We observe that when training from scratch TCC features perform better on both phase progression and Kendall's Tau for both the datasets. Additionally, we note that Kendall's Tau (which measures alignment between sequences using nearest neighbors matching) is significantly higher when we learn features using the combined losses. TCC + TCN outperforms both supervised learning and self-supervised learning methods significantly for both the datasets for fine-grained tasks.
Applications

Cross-modal transfer in Videos. We are able to align a dataset of related videos without supervision. The alignment across videos enables transfer of annotations or other modalities from one video to another. For example, we can use this technique to transfer text annotations to an entire dataset of related videos by only labeling one video. One can also transfer other modalities associated with time like sound. We can hallucinate the sound of pouring liquids from one video to another purely on the basis of visual representations. We copy over the sound from the retrieved nearest neighbors and stitch the sounds together by simply concatenating the retrieved sounds. No other post-processing step is used. The results are in the supplementary material.
Fine-grained retrieval in Videos. We can use the nearest neighbours for fine-grained retrieval in a set of videos. In Figure 7, we show that we can retrieve frames when the glass is half full (Row 1) or when the hand has just placed the container back after pouring (Row 2). Note that in all retrieved examples, the liquid has already been transferred to the target container. For the Baseball Pitch class, the learned representations can even differentiate between the frames when the leg was up before the ball was pitched (Row 3) and after the ball was pitched (Row 4).
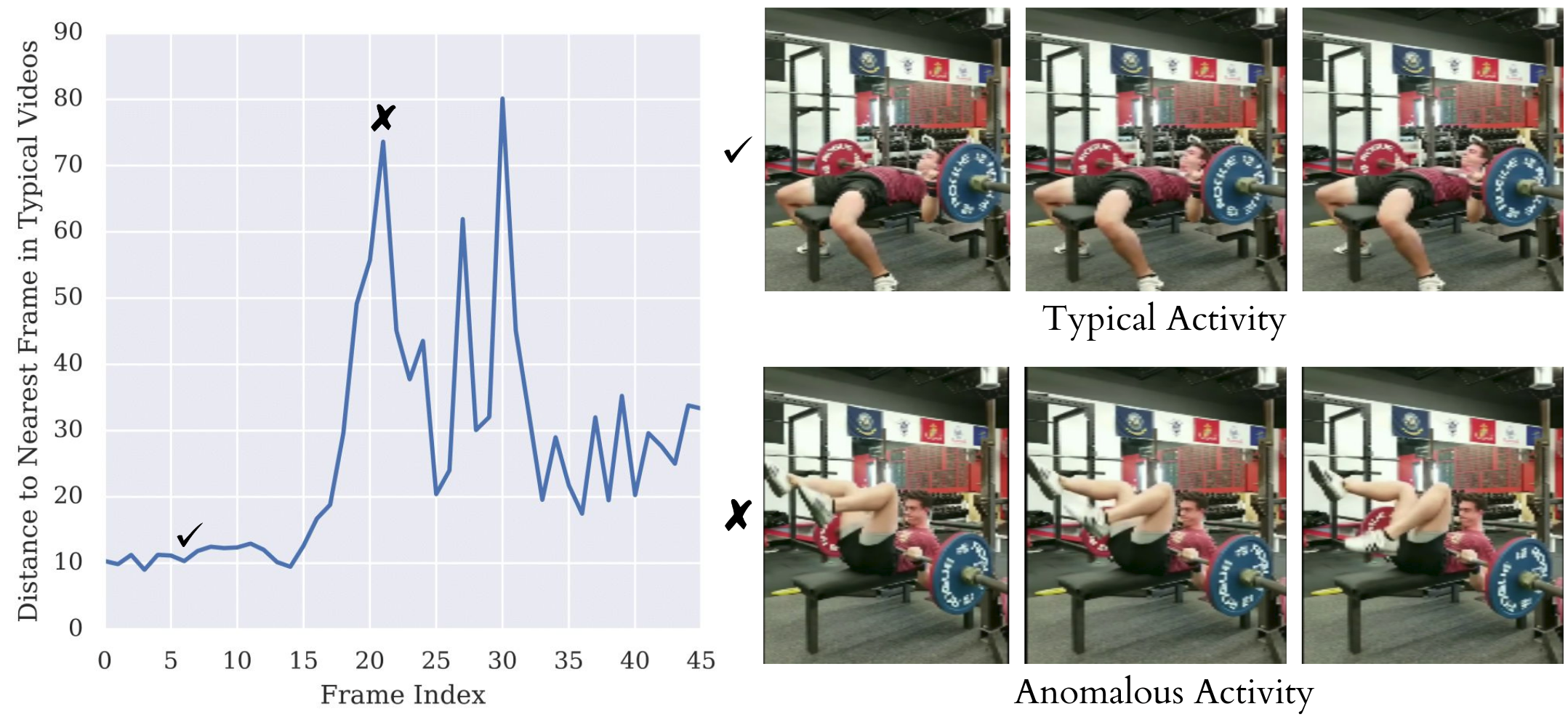
Anomaly detection. Since we have well-behaved nearest neighbors in the TCC embedding space, we can use the distance from an ideal trajectory in this space to detect anomalous activities in videos. If a video's trajectory in the embedding space deviates too much from the ideal trajectory, we can mark those frames as anomalous. We present an example of a video of a person attempting to bench-press in Figure 8. In the beginning the distance of the nearest neighbor is quite low. But as the video progresses, we observe a sudden spike in this distance (around the frame) where the person's activity is very different from the ideal bench-press trajectory.
Synchronous Playback. Using the learned alignments, we can transfer the pace of a video to other videos of the same action. We include examples of different videos playing synchronously in the supplementary material.
Conclusion
In this paper, we present a self-supervised learning approach that is able to learn features useful for temporally fine-grained tasks. In multiple experiments, we find self-supervised features lead to significant performance boosts when there is a lack of labeled data. With only one labeled video, TCC achieves similar performance to supervised learning models trained with about 50 videos. Additionally, TCC is more than a proxy task for representation learning. It serves as a general-purpose temporal alignment method that works without labels and benefits any task (like annotation transfer) which relies on the alignment itself.