Debidatta Dwibedi
|
I am a Senior Research Scientist in Google Deepmind. I completed my Masters in Robotics from the Robotics Institute at CMU, where I was advised by Martial Hebert. Prior to that I completed my undergrad from IIT Kanpur, where I worked with Amitabha Mukerjee.
Email / Google Scholar / GitHub / LinkedIn / Twitter Publications / Patents / Talks / Theses / Misc |
 |
ResearchMy research lies at the intersection of machine learning, computer vision and robotics. Presently, I am working on improving vision language models. |
Publications | |||||||||||||||||||||||||||||||||
|
paper |
project |
abstract |
bibtex
We introduce a versatile flexible-captioning vision-language model (VLM) capable of generating region-specific descriptions of varying lengths. The model, FlexCap, is trained to produce length-conditioned captions for input bounding boxes, and this allows control over the information density of its output, with descriptions ranging from concise object labels to detailed captions. To achieve this we create large-scale training datasets of image region descriptions of varying length, starting from captioned images. This flexible-captioning capability has several valuable applications. First, FlexCap demonstrates superior performance in dense captioning tasks on the Visual Genome dataset. Second, a visual question answering (VQA) system can be built by employing FlexCap to generate localized descriptions as inputs to a large language model. The resulting system achieves state-of-the-art zero-shot performance on a number of VQA datasets. We also demonstrate a localize-then-describe approach with FlexCap can be better at open-ended object detection than a describe-then-localize approach with other VLMs. We highlight a novel characteristic of FlexCap, which is its ability to extract diverse visual information through prefix conditioning. Finally, we qualitatively demonstrate FlexCap's broad applicability in tasks such as image labeling, object attribute recognition, and visual dialog.
|
|
paper |
project |
abstract |
bibtex
While large-scale robotic systems typically rely on textual instructions for tasks, this work explores a different approach: Can robots infer the task directly from observing humans? This shift necessitates the robot's ability to decode human intent and translate it into executable actions within its own physical constraints and environment. We introduce Vid2Robot, a novel end-to-end video-based learning framework for robots. Given a video demonstration of a manipulation task and current visual observations, Vid2Robot directly produces robot actions. This is achieved through a unified representation model trained on a large dataset of human video and robot trajectory. The model leverages cross-attention mechanisms to fuse prompt video features to the robot's current state and generate appropriate actions that mimic the observed task. To further improve policy performance, we propose auxiliary contrastive losses that enhance the alignment between human and robot video representations. We evaluate Vid2Robot on real-world robots, demonstrating a 23% improvement in performance compared to other video-conditioned policies when using human demonstration videos. Additionally, our model exhibits emergent capabilities, such as successfully transferring observed motions from one object to another, and long-horizon composition, thus showcasing its potential for real-world applications.
|
|
paper |
project |
abstract
Diverse demonstration datasets have powered significant advances in robot learning, but the dexterity and scale of such data can be limited by the hardware cost, the hardware robustness, and the ease of teleoperation. We introduce ALOHA 2, an enhanced version of ALOHA that has greater performance, ergonomics, and robustness compared to the original design. To accelerate research in large-scale bimanual manipulation, we open source all hardware designs of ALOHA 2 with a detailed tutorial, together with a MuJoCo model of ALOHA 2 with system identification. 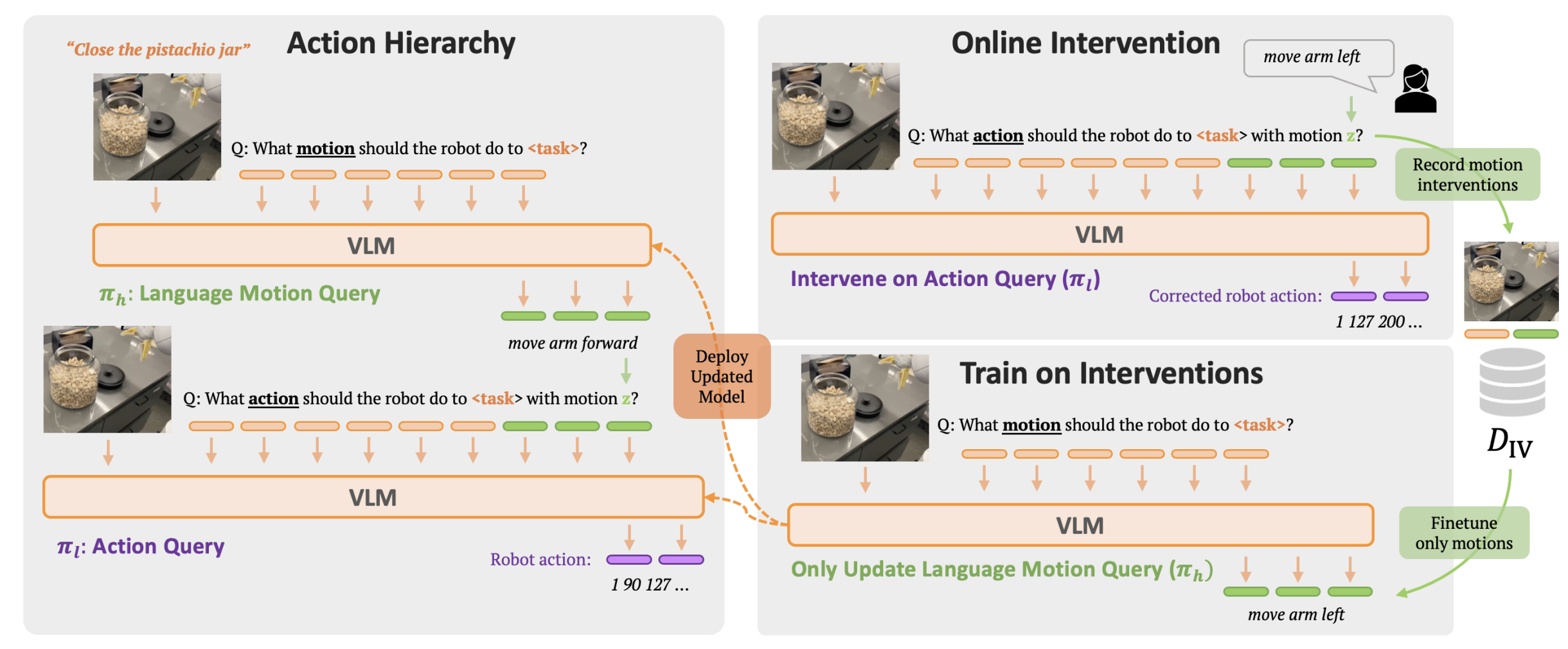
|
paper |
project |
abstract |
bibtex
Language provides a way to break down complex concepts into digestible pieces. Recent works in robot imitation learning use language-conditioned policies that predict actions given visual observations and the high-level task specified in language. These methods leverage the structure of natural language to share data between semantically similar tasks (e.g., "pick coke can" and "pick an apple") in multi-task datasets. However, as tasks become more semantically diverse (e.g., "pick coke can" and "pour cup"), sharing data between tasks becomes harder, so learning to map high-level tasks to actions requires much more demonstration data. To bridge tasks and actions, our insight is to teach the robot the language of actions, describing low-level motions with more fine-grained phrases like "move arm forward". Predicting these language motions as an intermediate step between tasks and actions forces the policy to learn the shared structure of low-level motions across seemingly disparate tasks. Furthermore, a policy that is conditioned on language motions can easily be corrected during execution through human-specified language motions. This enables a new paradigm for flexible policies that can learn from human intervention in language. Our method RT-H builds an action hierarchy using language motions: it first learns to predict language motions, and conditioned on this and the high-level task, it predicts actions, using visual context at all stages. We show that RT-H leverages this language-action hierarchy to learn policies that are more robust and flexible by effectively tapping into multi-task datasets. We show that these policies not only allow for responding to language interventions, but can also learn from such interventions and outperform methods that learn from teleoperated interventions. 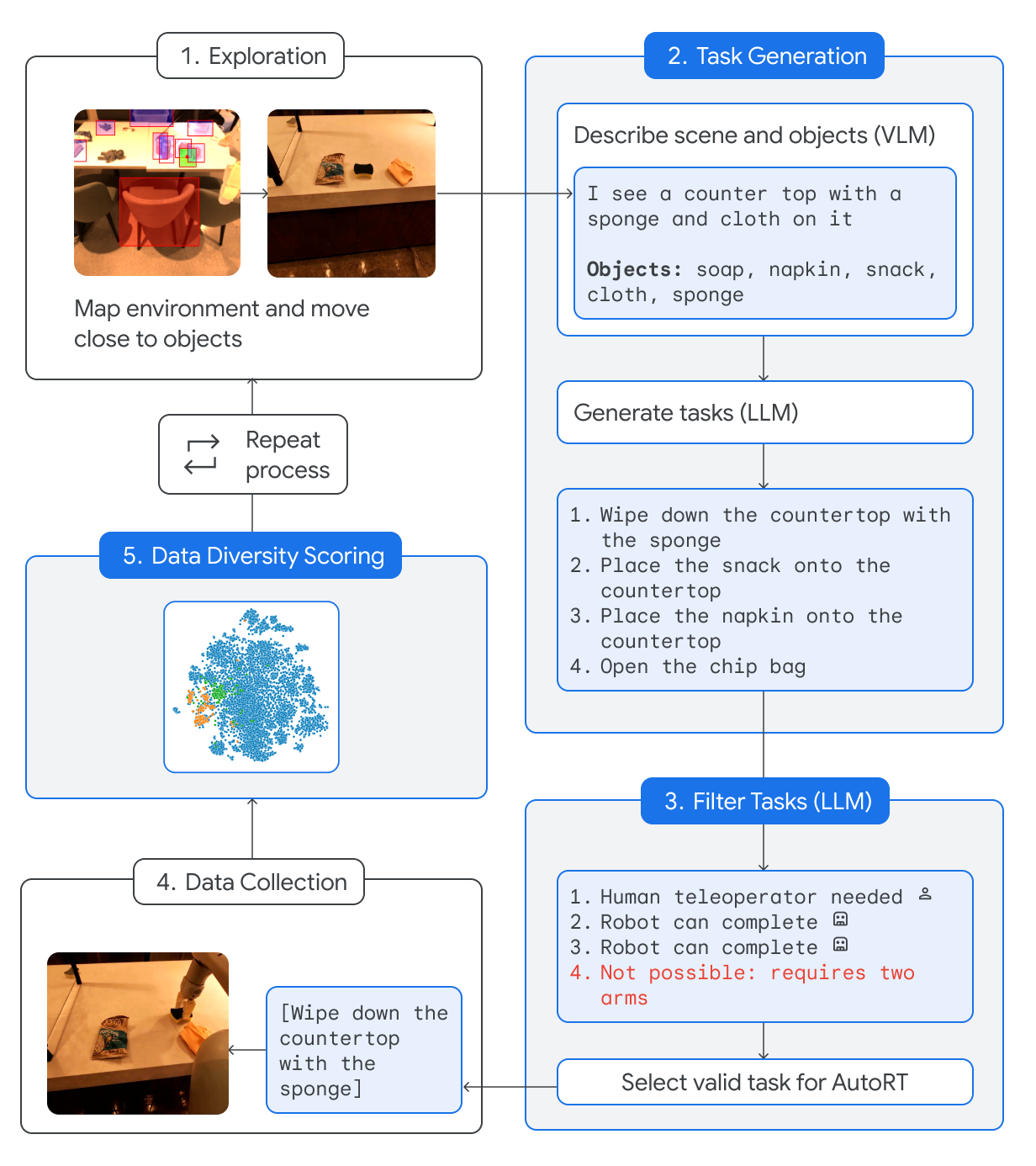
|
paper |
project |
abstract |
bibtex
Foundation models that incorporate language, vision, and more recently actions have revolutionized the ability to harness internet scale data to reason about useful tasks. However, one of the key challenges of training embodied foundation models is the lack of data grounded in the physical world. In this paper, we propose AutoRT, a system that leverages existing foundation models to scale up the deployment of operational robots in completely unseen scenarios with minimal human supervision. AutoRT leverages vision-language models (VLMs) for scene understanding and grounding, and further uses large language models (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots. Guiding data collection by tapping into the knowledge of foundation models enables AutoRT to effectively reason about autonomy tradeoffs and safety while significantly scaling up data collection for robot learning. We demonstrate AutoRT proposing instructions to over 20 robots across multiple buildings and collecting 77k real robot episodes via both teleoperation and autonomous robot policies. We experimentally show that such "in-the-wild" data collected by AutoRT is significantly more diverse, and that AutoRT's use of LLMs allows for instruction following data collection robots that can align to human preferences. 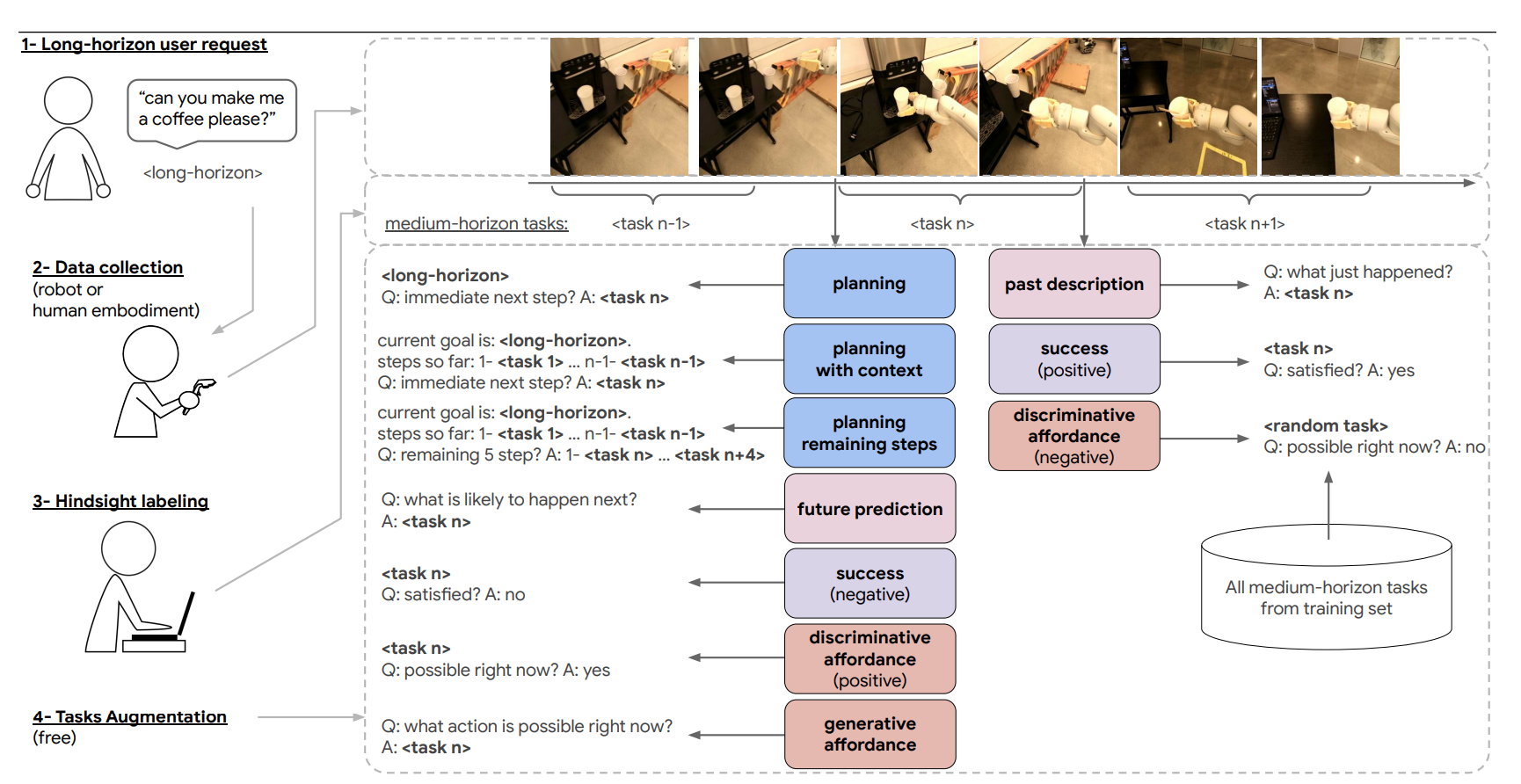
|
paper |
project |
dataset |
abstract |
bibtex
We present a scalable, bottom-up and intrinsically diverse data collection scheme that can be used for high-level reasoning with long and medium horizons and that has 2.2x higher throughput compared to traditional narrow top-down step-by-step collection. We collect realistic data by performing any user requests within the entirety of 3 office buildings and using multiple robot and human embodiments. With this data, we show that models trained on all embodiments perform better than ones trained on the robot data only, even when evaluated solely on robot episodes. We find that for a fixed collection budget it is beneficial to take advantage of cheaper human collection along with robot collection. We release a large and highly diverse (29,520 unique instructions) dataset dubbed RoboVQA containing 829,502 (video, text) pairs for robotics-focused visual question answering. We also demonstrate how evaluating real robot experiments with an intervention mechanism enables performing tasks to completion, making it deployable with human oversight even if imperfect while also providing a single performance metric. We demonstrate a single video-conditioned model named RoboVQA-VideoCoCa trained on our dataset that is capable of performing a variety of grounded high-level reasoning tasks in broad realistic settings with a cognitive intervention rate 46% lower than the zero-shot state of the art visual language model (VLM) baseline and is able to guide real robots through long-horizon tasks. The performance gap with zero-shot state-of-the-art models indicates that a lot of grounded data remains to be collected for real-world deployment, emphasizing the critical need for scalable data collection approaches. Finally, we show that video VLMs significantly outperform single-image VLMs with an average error rate reduction of 19% across all VQA tasks. 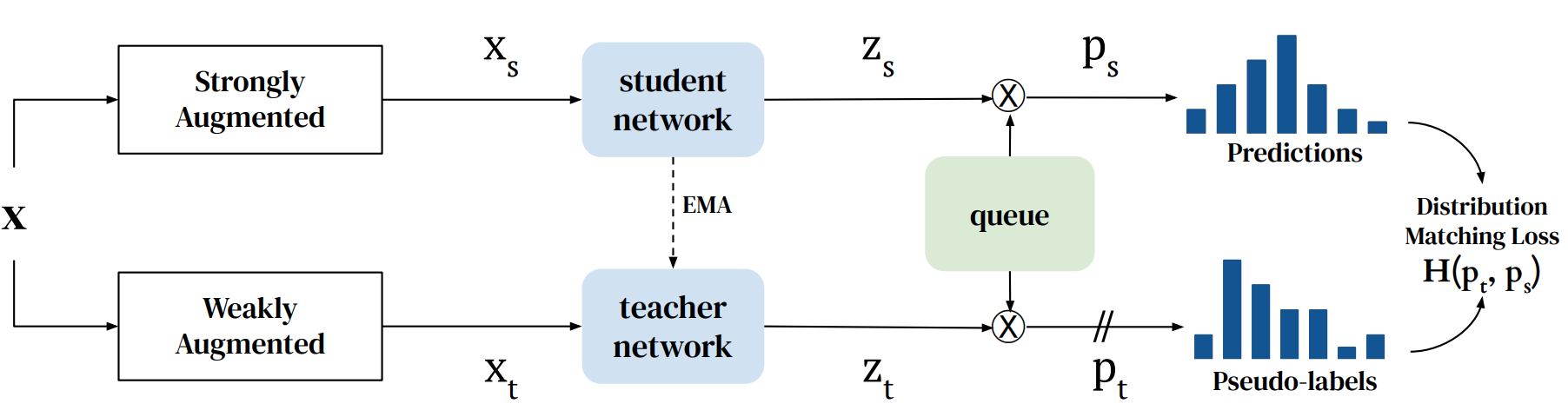
|
paper |
code |
abstract |
bibtex
In semi-supervised learning, student-teacher distribution matching has been successful in improving performance of models using unlabeled data in conjunction with few labeled samples. In this paper, we aim to replicate that success in the self-supervised setup where we do not have access to any labeled data during pre-training. We introduce our algorithm, Q-Match, and show it is possible to induce the student-teacher distributions without any knowledge of downstream classes by using a queue of embeddings of samples from the unlabeled dataset. We focus our study on tabular datasets and show that Q-Match outperforms previous self-supervised learning techniques when measuring downstream classification performance. Furthermore, we show that our method is sample efficient--in terms of both the labels required for downstream training and the amount of unlabeled data required for pre-training--and scales well to the sizes of both the labeled and unlabeled data. 
|
paper |
project |
abstract |
bibtex
Perceptual understanding of the scene and the relationship between its different components is important for successful completion of robotic tasks. Representation learning has been shown to be a powerful technique for this, but most of the current methodologies learn task specific representations that do not necessarily transfer well to other tasks. Furthermore, representations learned by supervised methods require large labeled datasets for each task that are expensive to collect in the real world. Using self-supervised learning to obtain representations from unlabeled data can mitigate this problem. However, current self-supervised representation learning methods are mostly object agnostic, and we demonstrate that the resulting representations are insufficient for general purpose robotics tasks as they fail to capture the complexity of scenes with many components. In this paper, we explore the effectiveness of using object-aware representation learning techniques for robotic tasks. Our self-supervised representations are learned by observing the agent freely interacting with different parts of the environment and is queried in two different settings: (i) policy learning and (ii) object location prediction. We show that our model learns control policies in a sample-efficient manner and outperforms state-of-the-art object agnostic techniques as well as methods trained on raw RGB images. Our results show a 20 percent increase in performance in low data regimes (1000 trajectories) in policy training using implicit behavioral cloning (IBC). Furthermore, our method outperforms the baselines for the task of object localization in multi-object scenes. 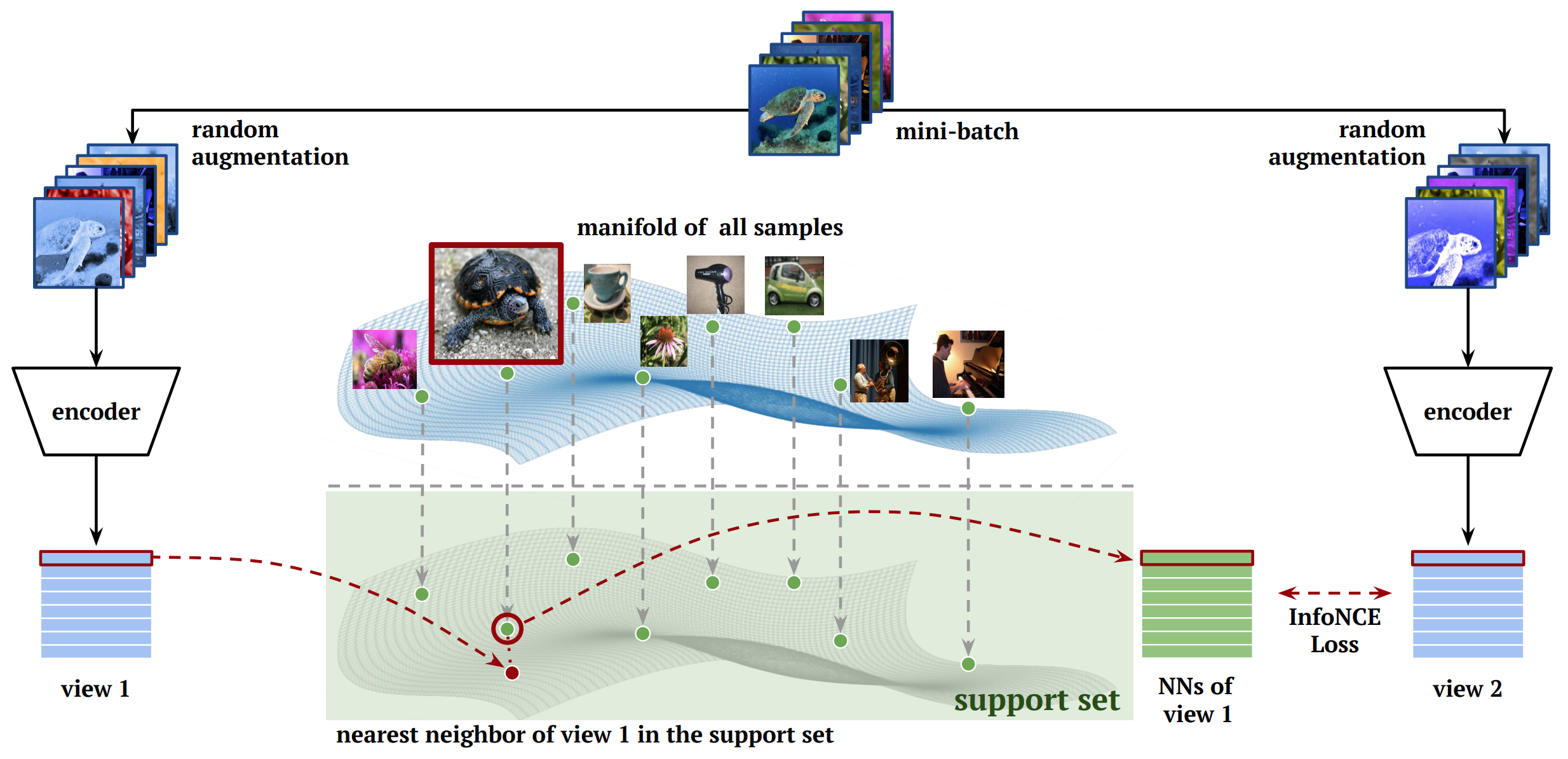
|
paper |
abstract |
bibtex
Self-supervised learning algorithms based on instance discrimination train encoders to be invariant to pre-defined transformations of the same instance. While most methods treat different views of the same image as positives for a contrastive loss, we are interested in using positives from other instances in the dataset. Our method, Nearest-Neighbor Contrastive Learning of visual Representations (NNCLR), samples the nearest neighbors from the dataset in the latent space, and treats them as positives. This provides more semantic variations than pre-defined transformations. We find that using the nearest-neighbor as positive in contrastive losses improves performance significantly on ImageNet classification, from 71.7% to 75.6%, outperforming previous state-of-the-art methods. On semi-supervised learning benchmarks we improve performance significantly when only 1% ImageNet labels are available, from 53.8% to 56.5%. On transfer learning benchmarks our method outperforms state-of-the-art methods (including supervised learning with ImageNet) on 8 out of 12 downstream datasets. Furthermore, we demonstrate empirically that our method is less reliant on complex data augmentations. We see a relative reduction of only 2.1% ImageNet Top-1 accuracy when we train using only random crops. 
|
paper |
abstract |
bibtex |
project |
code
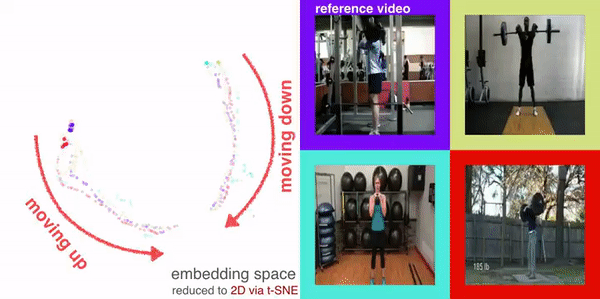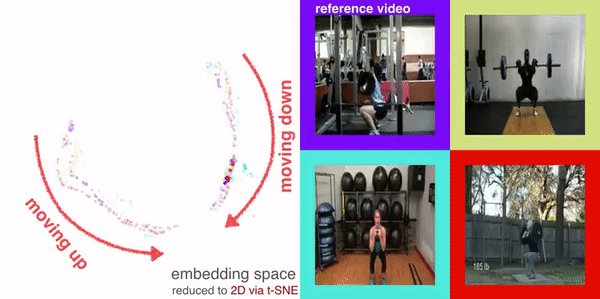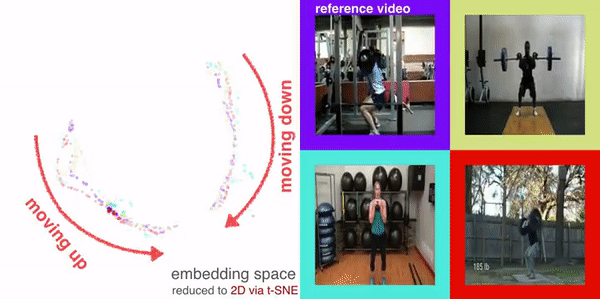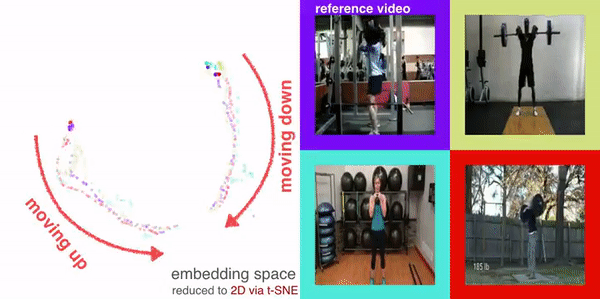
We investigate the visual cross-embodiment imitation setting, in which agents learn policies from videos of other agents (such as humans) demonstrating the same task, but with stark differences in their embodiments -- shape, actions, end-effector dynamics, etc. In this work, we demonstrate that it is possible to automatically discover and learn vision-based reward functions from cross-embodiment demonstration videos that are robust to these differences. Specifically, we present a self-supervised method for Cross-embodiment Inverse Reinforcement Learning (XIRL) that leverages temporal cycle-consistency constraints to learn deep visual embeddings that capture task progression from offline videos of demonstrations across multiple expert agents, each performing the same task differently due to embodiment differences. Prior to our work, producing rewards from self-supervised embeddings typically required alignment with a reference trajectory, which may be difficult to acquire under stark embodiment differences. We show empirically that if the embeddings are aware of task progress, simply taking the negative distance between the current state and goal state in the learned embedding space is useful as a reward for training policies with reinforcement learning. We find our learned reward function not only works for embodiments seen during training, but also generalizes to entirely new embodiments. Additionally, when transferring real-world human demonstrations to a simulated robot, we find that XIRL is more sample efficient than current best methods. 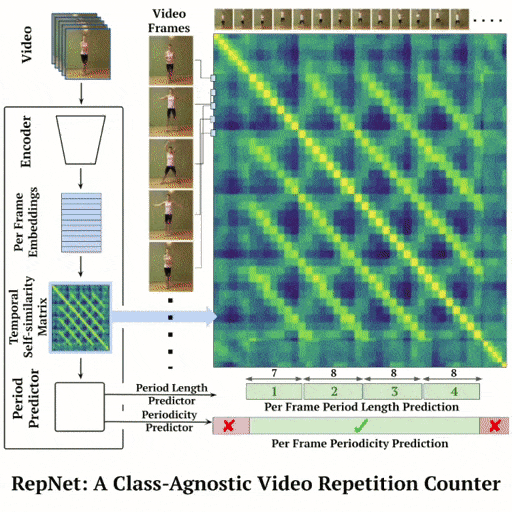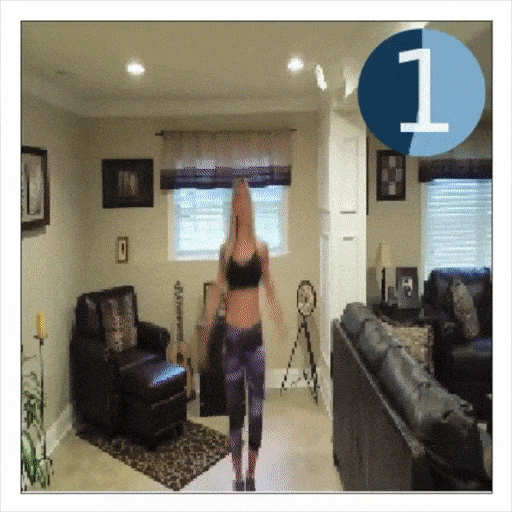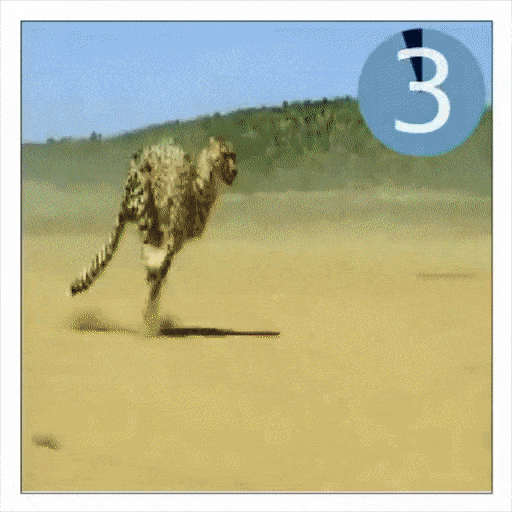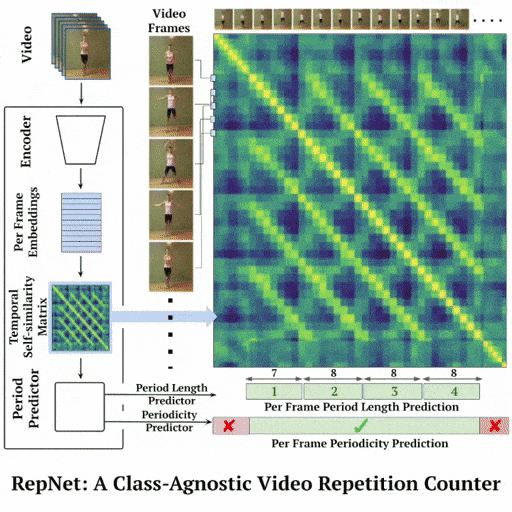
|
paper |
abstract |
bibtex |
project |
teaser video |
Google AI blogpost |
colab
We present an approach for estimating the period with which an action is repeated in a video. The crux of the approach lies in constraining the period prediction module to use temporal self-similarity as an intermediate representation bottleneck that allows generalization to unseen repetitions in videos in the wild. We train this model, called Repnet, with a synthetic dataset that is generated from a large unlabeled video collection by sampling short clips of varying lengths and repeating them with different periods and counts. This combination of synthetic data and a powerful yet constrained model, allows us to predict periods in a class-agnostic fashion. Our model substantially exceeds the state of the art performance on existing periodicity (PERTUBE) and repetition counting (QUVA) benchmarks. We also collect a new challenging dataset called Countix (~90 times larger than existing datasets) which captures the challenges of repetition counting in real-world videos. 
|
paper |
interactive paper |
abstract |
bibtex |
project |
poster |
Google AI blogpost |
code |
colab
We introduce a self-supervised representation learning method based on the task of temporal alignment between videos. The method trains a network using temporal cycle consistency (TCC), a differentiable cycle-consistency loss that can be used to find correspondences across time in multiple videos. The resulting per-frame embeddings can be used to align videos by simply matching frames using the nearest-neighbors in the learned embedding space. To evaluate the power of the embeddings, we densely label the Pouring and Penn Action video datasets for action phases. We show that (i) the learned embeddings enable few-shot classification of these action phases, significantly reducing the supervised training requirements; and (ii) TCC is complementary to other methods of self-supervised learning in videos, such as Shuffle and Learn and Time-Contrastive Networks. The embeddings are also used for a number of applications based on alignment (dense temporal correspondence) between video pairs, including transfer of metadata of synchronized modalities between videos (sounds, temporal semantic labels), synchronized playback of multiple videos, and anomaly detection. 
|
paper |
abstract |
bibtex |
code
We identify two issues with the family of algorithms based on the Adversarial Imitation Learning framework. The first problem is implicit bias present in the reward functions used in these algorithms. While these biases might work well for some environments, they can also lead to sub-optimal behavior in others. Secondly, even though these algorithms can learn from few expert demonstrations, they require a prohibitively large number of interactions with the environment in order to imitate the expert for many real-world applications. In order to address these issues, we propose a new algorithm called Discriminator-Actor-Critic that uses off-policy Reinforcement Learning to reduce policy-environment interaction sample complexity by an average factor of 10. Furthermore, since our reward function is designed to be unbiased, we can apply our algorithm to many problems without making any task-specific adjustments. 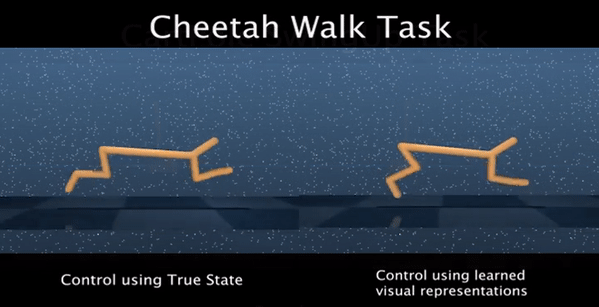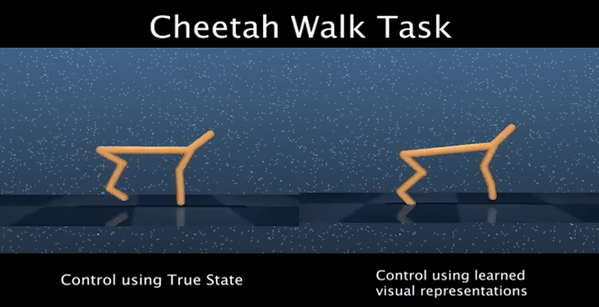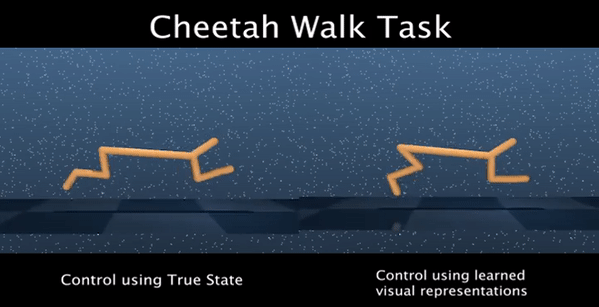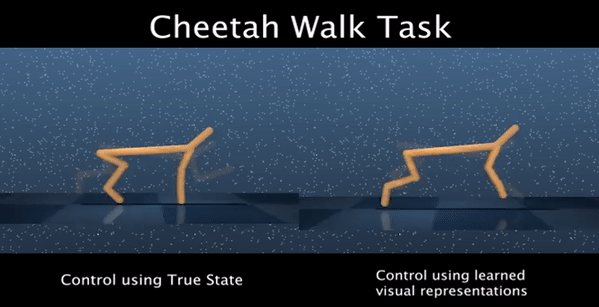
|
paper |
abstract |
bibtex |
project
In this work we explore a new approach for robots to teach themselves about the world simply by observing it. In particular we investigate the effectiveness of learning task-agnostic representations for continuous control tasks. We extend Time-Contrastive Networks (TCN) that learn from visual observations by embedding multiple frames jointly in the embedding space as opposed to a single frame. We show that by doing so, we are now able to encode both position and velocity attributes significantly more accurately. We test the usefulness of this self-supervised approach in a reinforcement learning setting. We show that the representations learned by agents observing themselves take random actions, or other agents perform tasks successfully, can enable the learning of continuous control policies using algorithms like Proximal Policy Optimization (PPO) using only the learned embeddings as input. We also demonstrate significant improvements on the real-world Pouring dataset with a relative error reduction of 39.4% for motion attributes and 11.1% for static attributes compared to the single-frame baseline. 
|
paper |
abstract |
bibtex |
code |
poster
A major impediment in rapidly deploying object detection models for instance detection is the lack of large annotated datasets. For example, finding a large labeled dataset containing instances in a particular kitchen is unlikely. Each new environment with new instances requires expensive data collection and annotation. In this paper, we propose a simple approach to generate large annotated instance datasets with minimal effort. Our key insight is that ensuring only patch-level realism provides enough training signal for current object detector models. We automatically `cut' object instances and `paste' them on random backgrounds. A naive way to do this results in pixel artifacts which result in poor performance for trained models. We show how to make detectors ignore these artifacts during training and generate data that gives competitive performance on real data. Our method outperforms existing synthesis approaches and when combined with real images improves relative performance by more than 21% on benchmark datasets. In a cross-domain setting, our synthetic data combined with just 10% real data outperforms models trained on all real data. 
|
paper |
abstract |
bibtex
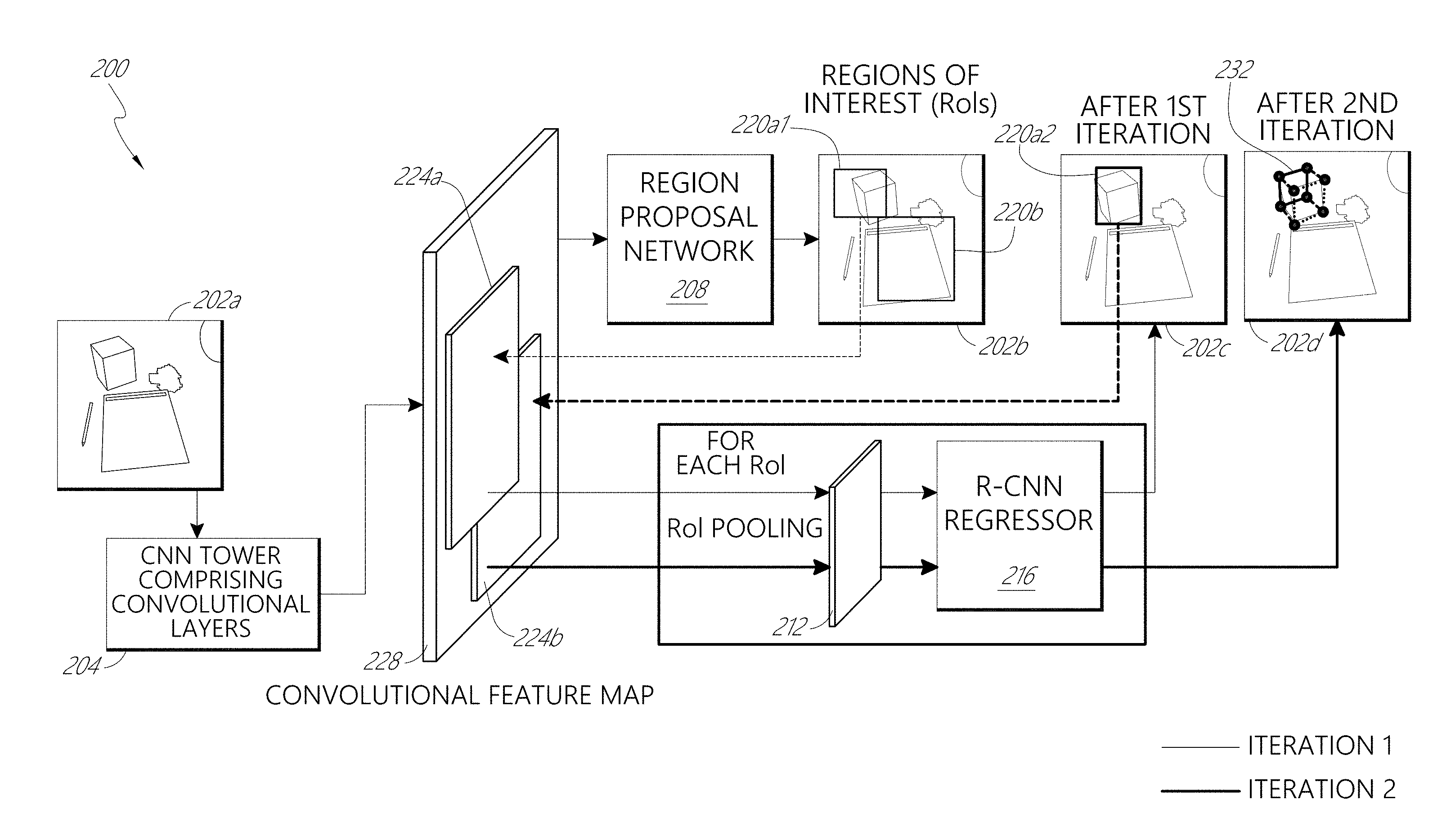
We present a Deep Cuboid Detector which takes a consumer-quality RGB image of a cluttered scene and localizes all 3D cuboids (box-like objects). Contrary to classical approaches which fit a 3D model from low-level cues like corners, edges, and vanishing points, we propose an end-to-end deep learning system to detect cuboids across many semantic categories (e.g., ovens, shipping boxes, and furniture). We localize cuboids with a 2D bounding box, and simultaneously localize the cuboid's corners, effectively producing a 3D interpretation of box-like objects. We refine keypoints by pooling convolutional features iteratively, improving the baseline method significantly. Our deep learning cuboid detector is trained in an end-to-end fashion and is suitable for real-time applications in augmented reality (AR) and robotics. 
|
paper |
abstract |
bibtex |
videos
Where do the predicates in a game ontology come from? We use RGBD vision to learn a) the spatial structure of a board, and b) the number of parameters in a move or transition. These are used to define state-transition predicates for a logical description of each game state. Given a set of videos for a game, we use an improved 3D multi-object tracking to obtain the positions of each piece in games such as 4-peg solitaire or Towers of Hanoi. The spatial positions occupied by pieces over the entire game is clustered, revealing the structure of the board. Each frame is represented as a Semantic Graph with edges encoding spatial relations between pieces. Changes in the graphs between game states reveal the structure of a “move”. Knowledge from spatial structure and semantic graphs is mapped to FOL descriptions of the moves and used in an Inductive Logic framework to infer the valid moves and other rules of the game. Discovered predicate structures and induced rules are demonstrated for several games with varying board layouts and move structures. |
Patents |
|
Talks |
|
|
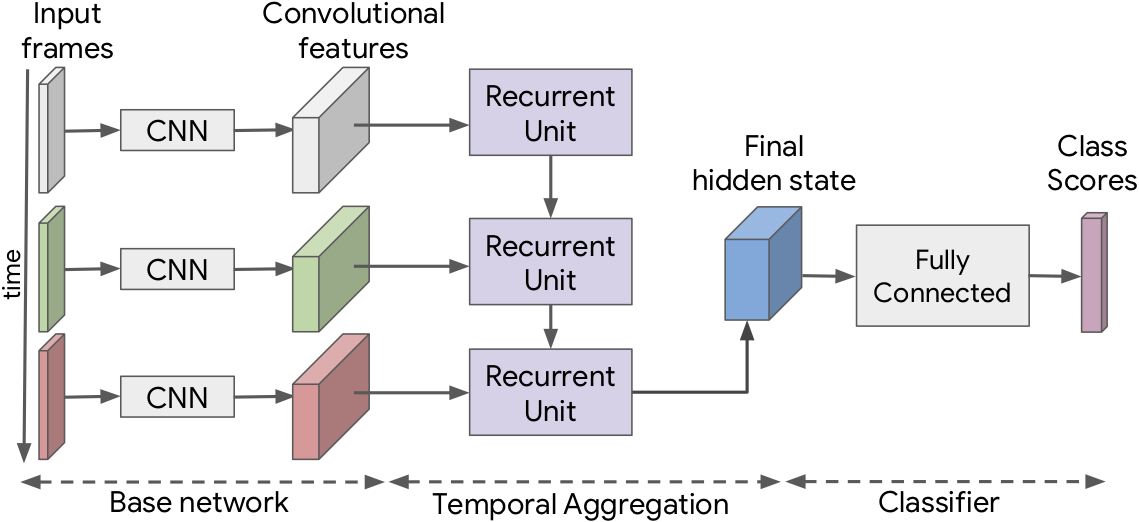
|
|
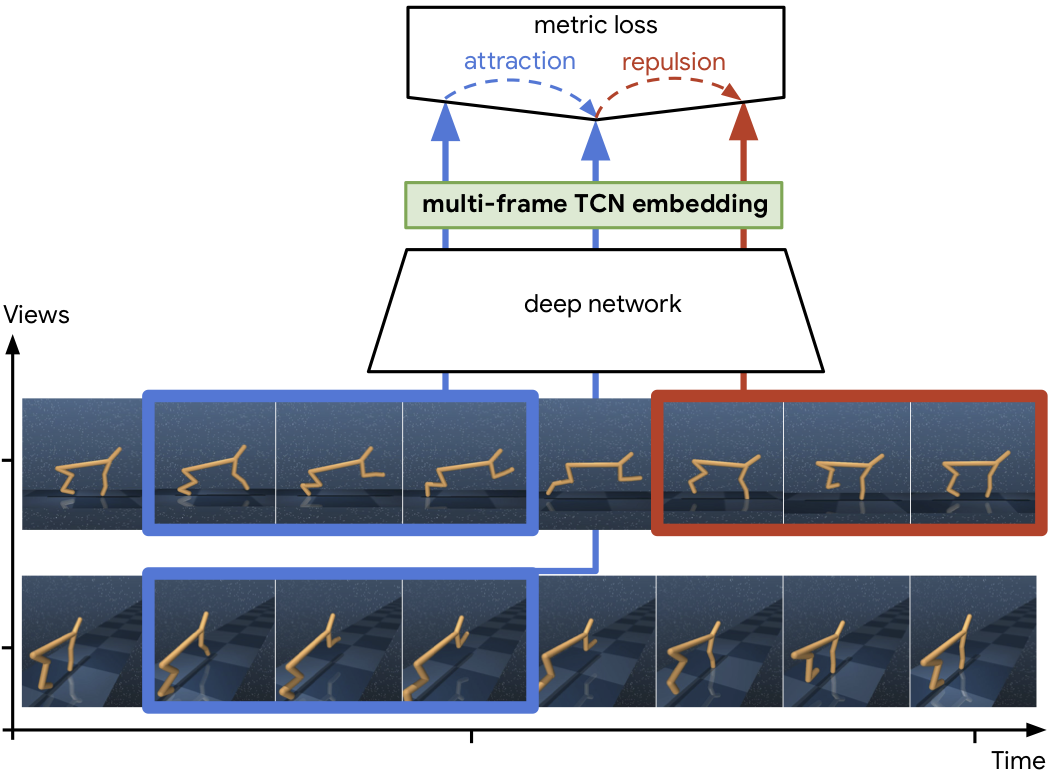
|
|
Theses |

|
|

|
|
MiscellaneousSome other unpublished work: |

| |
|
|

|
|

|
|
|